The talk started with Jitendra saying image search does not work well. To back this claim, he showed screen shots of searches on Google Image Search and Flickr for [monkey] and highlighted the false positives.
Jitendra then claimed that neither better analysis of the text around images nor more tagging will solve this problem because these techniques are missing the semantic component of images, that is, the shapes, concepts, and categories represented by the objects in the image.
Arguing that we need to move "from pixels to perception", Jitendra pushed for "category recognition" for objects in images where "objects have parts" and form a "partonomy", a hierarchical grouping of object parts. He said current attempts at this have at most 100 parts in the partonomy, but it appears humans commonly use 2-3 orders of magnitude more, 30k+ parts, when doing object recognition.
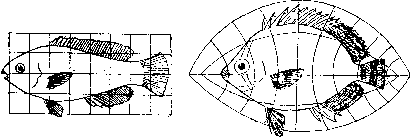
A common theme running through the talk was having a baseline model of a part, then being able to deform the part to match most variations. For example, he showed some famous examples from the 1917 text "On growth and form"
A near the end of the talk, Jitendra contrasted the techniques used for face detection, which he called "a solved problem", with the techniques he thought would be necessary for general object and part recognition. He argued that the techniques used on face detection, to slide various sized windows across the image looking for things that have a face pattern to them, would both be too computationally expensive and have too high a false positive rate to do for 30k objects/parts. Jitendra said something new would have to be created to deal with large scale object recognition.
What that something new is is not clear, but Jitendra seemed to me to be pushing for a system that is biologically inspired, perhaps quickly coming up with rough candidate sets of interpretations of parts of the image, discounting interpretations that violate prior knowledge on objects that tend to occur nearby to each other, then repeating at additional levels of detail until steady state is reached.
Doing object recognition quickly, reliably, and effectively to find meaning in images remains a big, hairy, unsolved research problem, and probably will be for some time, but, if Jitendra is correct, it is the only way to make significant progress in image search.
